
A sneak peek at what we’re learning — and an invitation to hear the full story
Picture an elderly man in central Texas, sitting at his kitchen table, talking about his childhood. He’s describing something ordinary — a neighbor, a memory, a piece of farm equipment — but the language coming out of his mouth is absolutely extraordinary.
He’s speaking Texas Czech.
It’s a dialect that developed in near-total isolation: 19th-century Moravian Czech, preserved in farming communities across central Texas for over a hundred years, absorbing English along the way in ways that linguists describe as unique and irreplaceable. And he, like most of the people who speak it fluently, is in his 80s or 90s.
When an AI transcription tool encounters his voice for the first time, something interesting happens. It tries its best. It gets some things right. And some of what it gets wrong tells you a lot about why this work matters.
The Race Against Time
Dr. Lida Cope — a native Czech linguist and professor of Applied Linguistics at East Carolina University — has been leading an international team in a race most people don’t know is happening. The Texas Czech Legacy Project has recorded hundreds of hours of interviews with elderly Texas Czech speakers: their stories, their memories, their language. The team has included transcribers at Charles University in Prague, researchers with deep Texas roots, and collaborators across two continents.
The work they’ve done is extraordinary. The problem is the math.
Hundreds of hours of recordings needed to be transcribed. At the pace that meticulous, expert-driven transcription requires — the only kind that does justice to a dialect this complex — completing the archive with a team of experienced transcribers could take 15 or more years. Most of the speakers don’t have 15 years. Some won’t have five. And TCLP doesn’t have a full-time team of transcribers.
That’s where I come in. 😊
I’m a Ph.D. Slavic linguist and former U.S. Government Technical executive, now volunteering my expertise to ask a specific question: can AI accelerate what Dr. Cope’s team has built, without compromising the quality they’ve spent 25 years establishing?
I also have a personal stake. My great-grandfather Jan Štěpán devoted decades to serving Czech immigrant communities in America, teaching English and helping people prepare for citizenship, teaching Czech at a Czech school in Cedar Rapids, and working with Czech-language newspapers. When I say this community’s heritage matters, I mean it in the most direct way possible. I am part of the Czech-American story I’m trying to preserve.
Tool #1: SONIX and the Standard Czech Problem
We first evaluated speech-to-text solutions, bearing in mind our extremely limited (non-existent) budget. The overwhelming winner was SONIX, a commercial platform which we are using mostly for its Speech to Text capabilities, although it does other things as well. We pointed it at the Texas Czech recordings and asked it to transcribe.
Here’s the thing about SONIX: it’s very good at Standard Czech — Spisovná čeština, the formal, modern Czech you’d find in newspapers or hear on national radio. Texas Czech is a Texas-based immigrant variety rooted mainly in 19th-century Moravian dialects, with some influence from standard Czech and a great deal of later English borrowing. It preserves older features, but it is not just a frozen 19th-century dialect.
SONIX did what any reasonable AI does when it encounters something unfamiliar: it reached for the closest thing it knew. Sometimes it was close. Sometimes the result was a phonetically plausible but completely wrong Standard Czech word standing in for a Texas Czech expression that has no Standard Czech equivalent. Sometimes it simply rendered English loanwords — words the speakers used naturally and fluently — as garbled approximations.
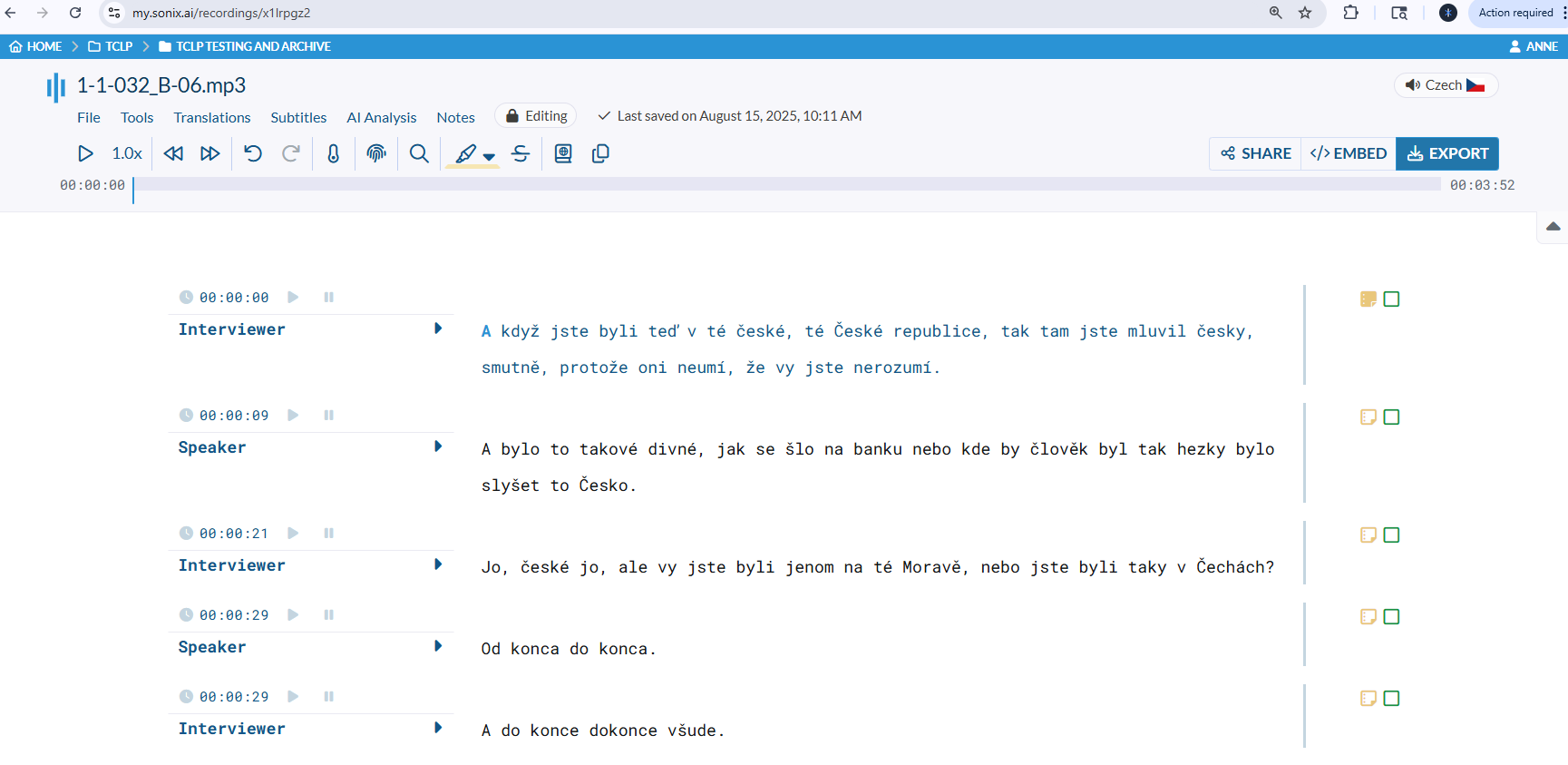
What SONIX produced was not a finished transcript. But here’s the thing: it was never supposed to be.
What SONIX produced was a first draft — a rough scaffold that gives human experts a running start instead of a blank page. For a 30-minute interview, that’s the difference between starting from nothing and starting from something 60-70% of the way there. For hundreds of hours of recordings, that difference is measured in years.
Tool #2: Turning Raw Transcripts into Research-Ready Archives
A rough transcript, even a good one, is not an archive. It’s a wall of text. For it to be useful — to researchers, to families, to the archives where this material is ultimately headed — it needs structure.
This is where a second layer of AI assistance enters the workflow.
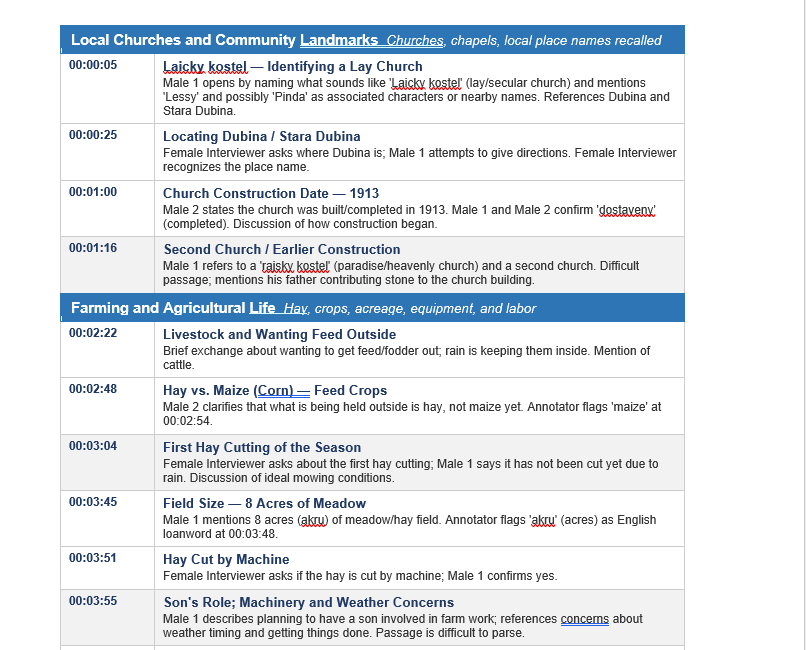
Using Claude (Anthropic’s AI), I’ve been processing SONIX transcripts into structured analysis documents: organized topic indexes, identified speaker segments, flagged personal and place names, and notes for the expert reviewers who will do the real linguistic work of correction and verification.
The division of labor is deliberate and important. AI handles volume and organization. Human experts handle truth.
Nothing in these transcript analysis documents is presented as a correction to the yet-to-be-perfected SONIX output — that’s not my role, and it’s not Claude’s role. Uncertain renderings get flagged with notation so reviewers can hear for themselves. The goal is to give Dr. Cope’s team a document they can work with efficiently, not a document that presumes to replace their judgment.
What comes out the other end looks like this: a formatted archival document with a timestamped topic index, categorized by theme, with speaker identifications and geographic references organized for fast review. Something a researcher anywhere in the world could navigate. Something a family could read to understand what their grandmother talked about.
The Detective Story: A Film, Lost Audio, and an Unexpected Match
Here’s where the project took an exciting turn.
In 1984, the folklorist Svatava Jakobson filmed Texas Czech speakers and communities. The footage survives. The audio does not.
The question sitting inside that gap: do any of the TCLP oral history recordings — interviews conducted separately, by Dr. Jakobson, Dr. Cope, and others — capture the same people who appear in the film? If so, you could potentially pair surviving footage with recorded voice, restoring something that seemed permanently lost.
We used AI to cross-reference the content of the TCLP transcripts against detailed scene-by-scene descriptions of the film. Names. Locations. Dates. Specific memories mentioned on camera.
What came back was a structured matching analysis — a spreadsheet mapping recordings to film scenes by probability of correspondence, flagged for Dr. Cope’s review. Some matches are strong. Some are speculative. All of them are leads that would have taken months to develop manually, now available for expert verification in a fraction of the time.
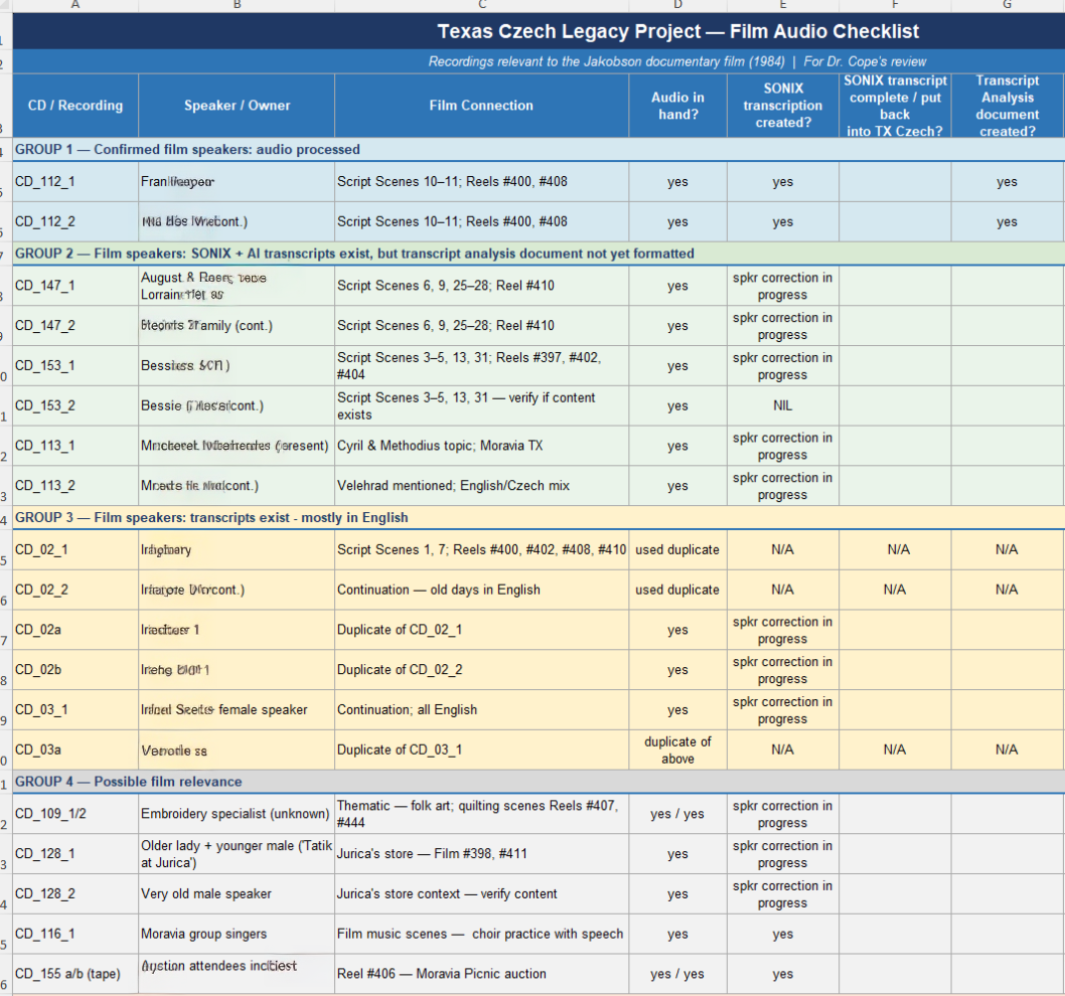
We found things. I’ll leave the details for the talk.
What This Actually Adds Up To
I want to be honest about what AI can and cannot do here, because the distinction matters.
AI cannot speak Texas Czech. It cannot hear the difference between a loanword and a transcription error the way a trained linguist can. It cannot make the judgment calls that 25 years of fieldwork and deep dialect knowledge make possible. Dr. Cope’s expertise is irreplaceable, and nothing in this workflow changes that.
What AI can do is handle the parts of the work that don’t require irreplaceable expertise — the organizing, the indexing, the cross-referencing, the first-draft scaffolding — so that the people who do have irreplaceable expertise can spend their time on the work only they can do.
That’s not AI replacing human knowledge. That’s AI multiplying it.
The stakes are personal, and they’re urgent. Somewhere in those hundreds of hours of recordings are stories that families don’t know exist yet. Descriptions of places that have changed beyond recognition. Songs. Recipes. Arguments. Jokes. The texture of a life lived in a language that is quietly disappearing.
The technology we’re testing right now could mean those stories reach the people they belong to while there are still people alive who remember the voices telling them.
Come Hear the Full Story
On May 16, 2 PM EDT (GMT-4), via Zoom, Dr. Lida Cope and I will be presenting together on the Texas Czech Legacy Project — what it is, how it was built, and what we’re learning about using AI to scale it. Dr. Cope will walk you through the project’s history, its international partnerships, and the linguistic significance of what’s being preserved. I’ll take you inside the AI workflow: the tools, the results, the surprises, and the limits.
The event is part of the National Museum of Language’s Speaker Series. For more information and to register, please visit: languagemuseum.org/speaker-series
If you’re curious about language preservation, AI in cultural heritage work, or simply want to hear what a dying dialect sounds like — we’d love to see you there.
And if you can’t make it in May: this blog is just getting started. The deeper dives into the AI experiments, the tools, the costs, and the human-machine partnership are coming in the articles ahead.
The voices are waiting. Let’s make sure they’re heard.
Anne Stepan is Principal Language Consultant at AC Stepan WordWorks and a volunteer consultant and analyst with the Texas Czech Legacy Project. She holds a Ph.D. in Slavic linguistics and brings extensive experience applying AI in high-stakes environments to cultural heritage preservation.